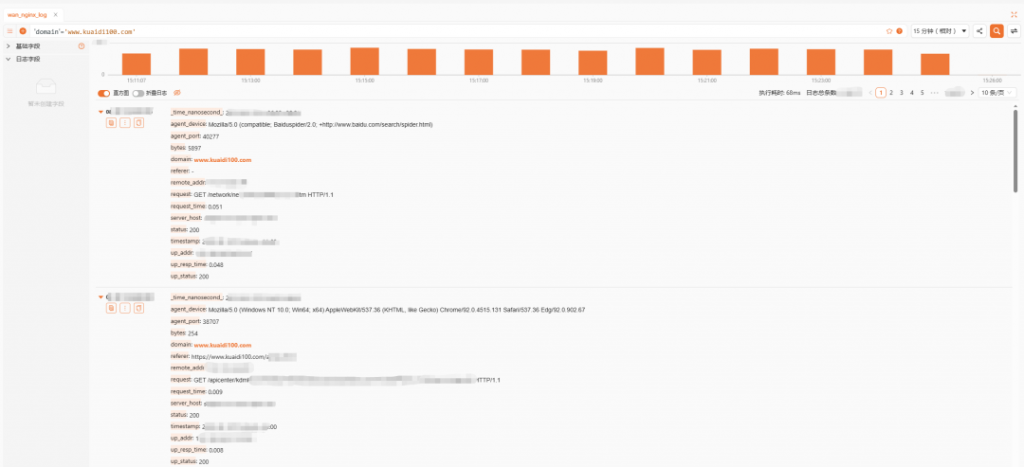
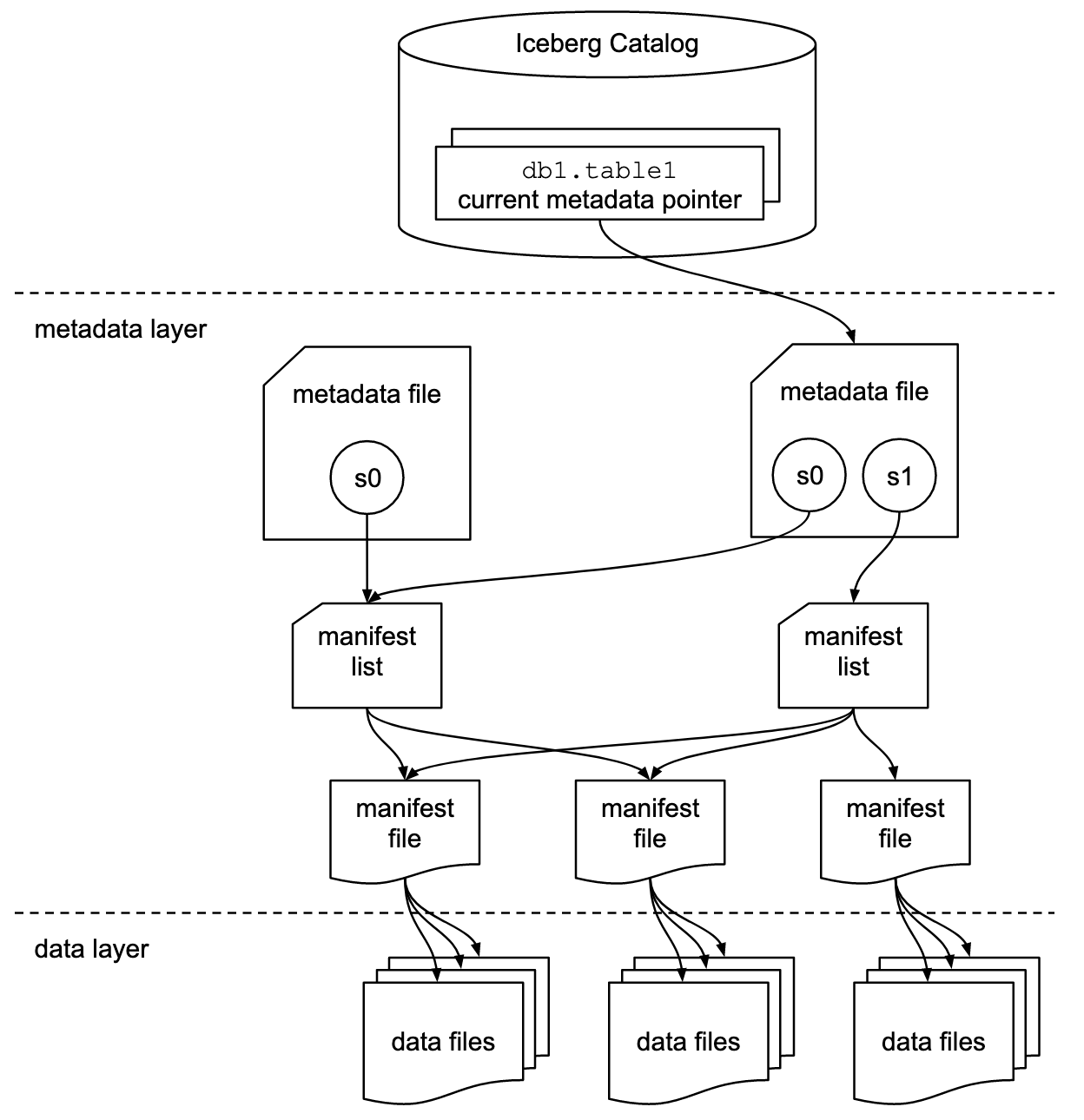
中间层是元数据层。其中 Metadata File 记录了表的存储位置、Schema 演化信息、分区演化信息以及所有的 Snapshot 和 Manifest List 信息,对应的是v1.metadata.json和v2.metadata.json文件,其中v后面的数字和version-hint.text文件中的数字对应,每当新增一个 Snapshot 的时候,version-hint.text中的数字加 1,同时也会新增一个vx.metadata.json文件,比如执行insert into hadoop_catalog.iceberg_db.user_log_iceberg values ('xxxxxxxxxxxxx', 'yyyyyyyyyyyyy', cast(1640986400 as timestamp))、delete from hadoop_catalog.iceberg_db.user_log_iceberg where udt = cast(1640986400 as timestamp)之后,版本就会变成v4:
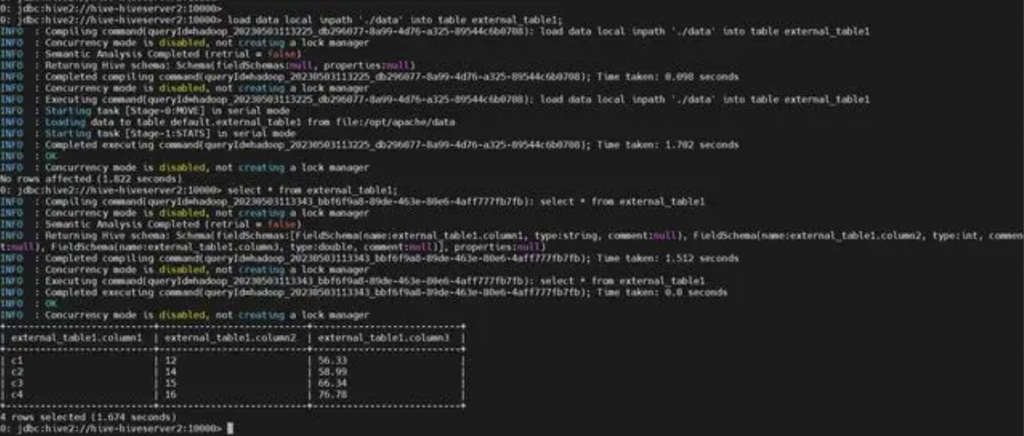
CREATE EXTERNAL TABLE external_table2 (
column1 STRING,
column2 INT,
column3 DOUBLE)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','LINES TERMINATED BY '\n'STORED AS TEXTFILELOCATION 'file:///path/to/local/file';### hive文件存储格式包括以下几类(STORED AS TEXTFILE):#1、TEXTFILE#2、SEQUENCEFILE#3、RCFILE#4、ORCFILE(0.11以后出现)#其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
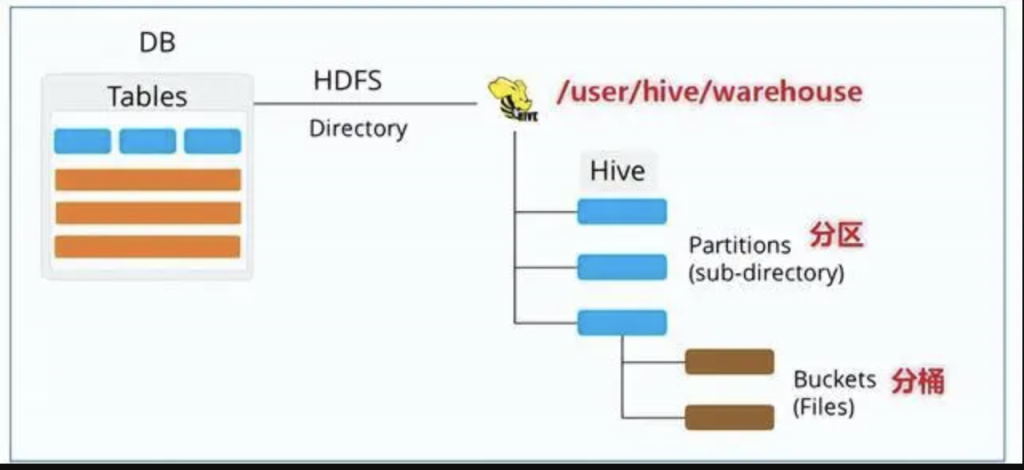
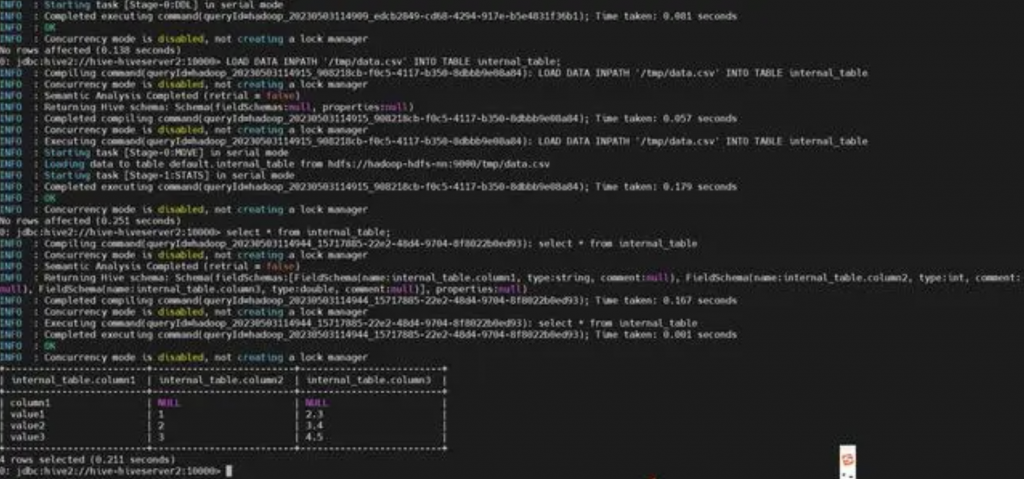
创建分区表的语法类似于创建普通表,只不过要使用 PARTITIONED BY 子句指定一个或多个分区列,例如:
# 内部表CREATE TABLE partitioned_internal_table (
id INT,
mesg STRING)PARTITIONED BY (
year INT,
month INT)
ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','LINES TERMINATED BY '\n'STORED AS TEXTFILE;
# 外部表
CREATE EXTERNAL TABLE partitioned_external_table (
id INT,
mesg STRING)PARTITIONED BY (
year INT,
month INT)
ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','LINES TERMINATED BY '\n'STORED AS TEXTFILELOCATION '/user/hive/partitioned_table/data';
LOAD DATA LOCAL INPATH './file.csv' INTO TABLE partitioned_external_table PARTITION (year=2019, month=1);# 查看分区show partitions partitioned_external_table;
在上述语句中,我们使用 LOAD DATA 子句将 /data/file.csv 文件加载到partitioned_table 表中,并指定了分区year为2019,分区month为1。
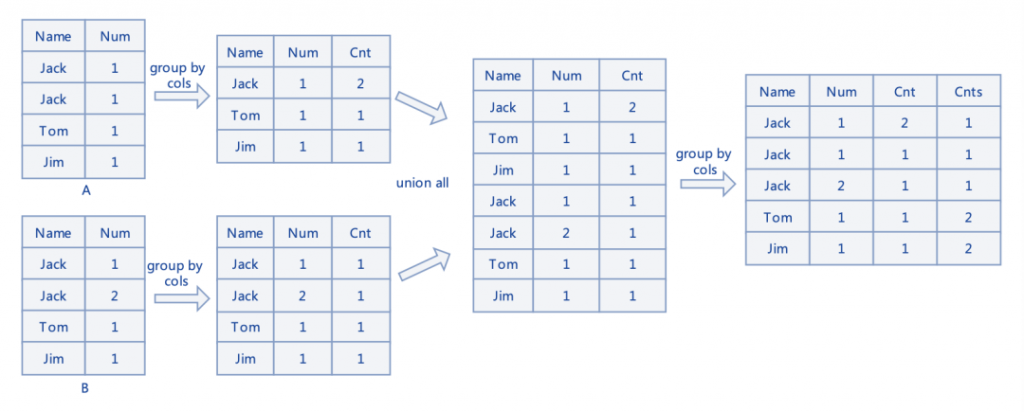
第一步将两表按所有列(这里是 name 和 num 字段)进行 GROUP BY,第二步 UNION ALL 两表数据,第三步再按所有列(这里是 name, num 和 cnt 字段) GROUP BY 一次产生最终表,在最终表中 cnts 值为2的行表示这行数据在两表中都有且重复值一致,对于值非2的数据就是差异行了。从上图的例子来说差异行 Jack|1|2|1 表示 Jack|1 这行数据数据在一个表中存在两行,结合差异行 Jack|1|1|1 来看其实就是 Jack|1 这行数据一个表有一行另一个表有两行。通过这个方式就可以对双跑产出的结果表进行一个全量的对比。通过这种结果对比方法可以完成大部分双跑任务的结果对比,但是对于结果表中存在 LIST、SET、MAP 这种容器类型的,因为在 toString 时顺序是无法保证的,所以会被识别为不一致,此外对于非稳定性的 SQL 如某列数据是 random 产生,因为每次执行产出的结果不一致,也会识别为对比失败,这两种情况下就需用人工的介入来分析了。
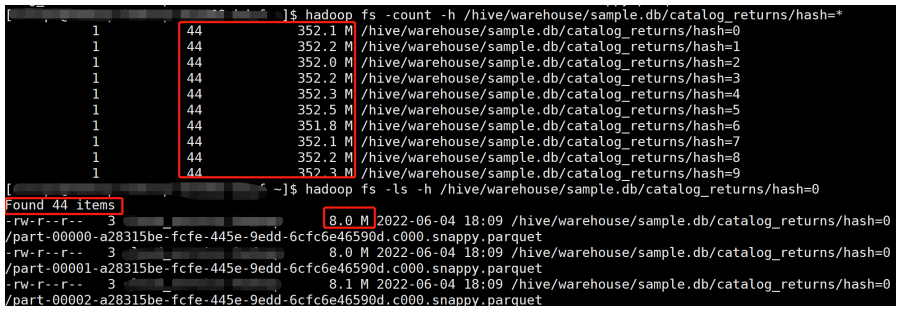
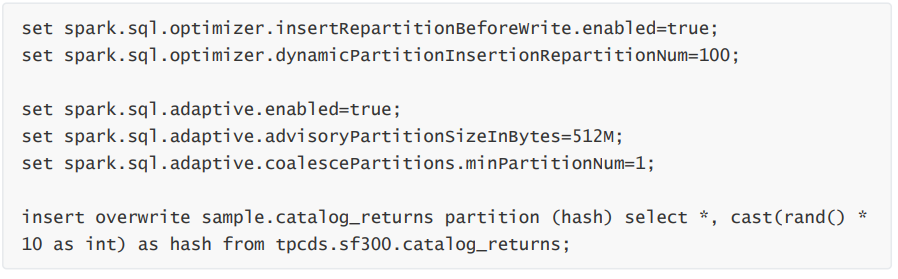
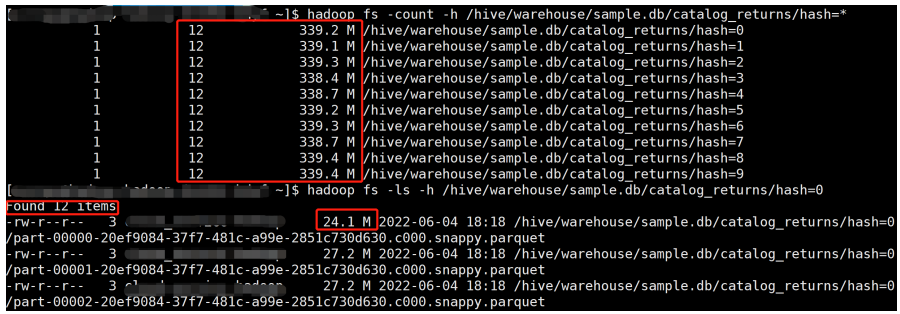
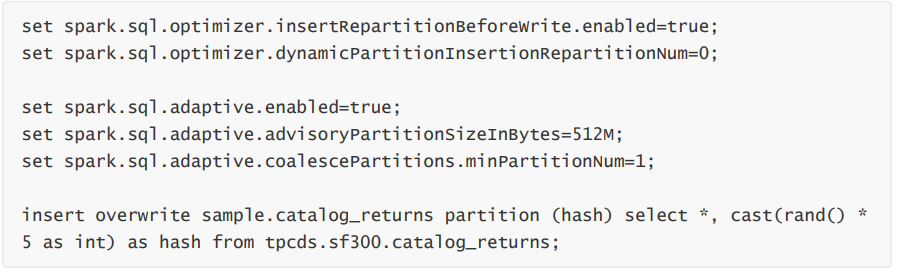
目前B站离线表存储主要使用 orc、parquet 格式,列式存储都支持一定程度的 data skipping,比如 orc 有三个级别的统计信息,file/stripe/row group,统计信息中会包含count,对于原始类型的列,还会记录 min/max 值,对于数值类型的列,也会记录 sum 值。在查询时,就可以根据不同粒度的统计信息以及 index 决定该 file/stripe/row 是否符合条件,不符合条件的直接跳过。对于统计信息及索引的细节见orc format (https://orc.apache.org/specification/ORCv1/) 和 orc index (https://orc.apache.org/docs/indexes.html) 。Parquet 与 orc 类似,也有相应的设计,具体见parquet format (https://github.com/apache/parquet-format) 和 parquet pageIndex (https://github.com/apache/parquet-format/blob/master/PageIndex.md) 。虽然 orc/parquet 都有 data skipping 的能力,但这种能力非常依赖数据的分布。前面提到统计信息中会包含每一列的 min/max 值,理论上如果查询条件(比如> < =)不在这个范围内,那么这个file/stripe/row group 就可以被跳过。但如果数据没有按照 filter 列排序,那最坏的情况下,可能每个 file/stripe/row group的min/max 值都一样,这样就造成任何粒度的数据都不能被跳过。为了增加列式存储 data skipping 效果,可以通过对数据增加额外的组织,如下:
select count(1) from tpcds.archive_spl_cluster where log_date = '20211124' and state = -16
表 archive_spl,不调整任何分布与排序
表 archive_spl_order,order by state,avid
通过对 state 进行 order 后 scan 阶段数据量直接从亿级别降至数十万级别。在生产中我们通过对 SQL 进行血缘分析找到那些热点表及高频 filter 列,将这些热列作为 table properties 存入 hms 中,在 Spark 执行时根据从 hms 中获取的列信息,通过相应的优化规则,物理计划自动增加 sort 算子,完成对数据组织。这个方案是基于列存优化数据组织来进行 data skipping,目前我们也在往索引方向上进一步探索。
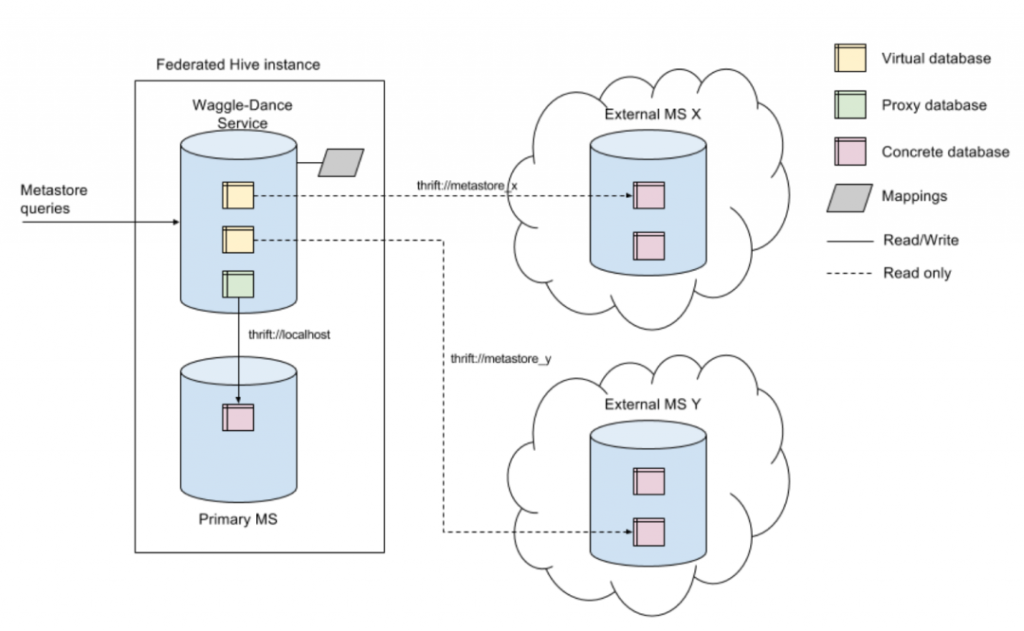
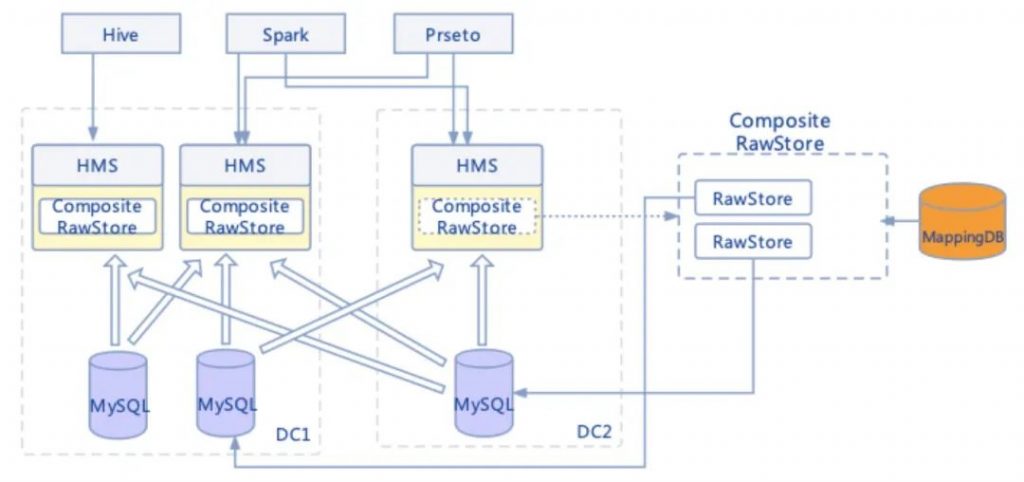
B站使用 HMS(Hive MetaStore)管理所有的离线表元信息,整个的离线计算的可用性都依赖 HMS 的稳定性。业务方在使用分区表时存在不少4级及以上分区的情况,有多个表分区数超百万。分区元信息庞大单次分区获取代价高,原生 HMS 基于单个 MySQL 实例存在性能瓶颈。
4.1 MetaStore Federation
随着多机房业务的推进,独立业务的 HDFS 数据和计算资源已经迁移到新机房,但是 HIVE 元数据仍在原有机房的 Mysql 中,这时候如果发生机房间的网络分区,就会影响新机房的任务。
为了解决上述问题,我们进行了方案调研,有两种方案供我们选择:
WaggleDance
HMS Federation
4.1.1 WaggleDance
WaggleDance是开源的一个项目(https://github.com/ExpediaGroup/waggle-dance),该项目主要是联合多个 HMS 的数据查询服务,实现了一个统一的路由接口解决多套 HMS 环境间的元数据共享问题。并且 WaggleDance 支持 HMS Client的接口调用。主要是通过 DB,把请求路由到对应的 HMS。
同时 HMS Federation 也提供了 Mysql 的横向扩容能力,允许一个机房可以有多个 Mysql 来存放 HIVE 元数据,如果单个 Mysql 的压力过大,可以把单个 Mysql 的数据存放到多个 Mysql 里面,分担 Mysql 的压力。比如主站业务的 HIVE 库,zhu_zhan 和 zhu_zhan_tmp,可以分别放在 idc1-mysql1 和 idc1-mysql2。
我们在 HMS Federation 中加入了一个 StateStore 的角色,该角色可以理解为一个路由器,HMS 在查询 Hive 库/表/分区之前,先问 StateStore 所要访问的 HIVE 元信息存放在哪一个 Mysql 中,获取到了对应的 Mysql 后,构建相应的ObjectStore,进行 SQL 拼接或者是利用 JDO 查询后端 Mysql。
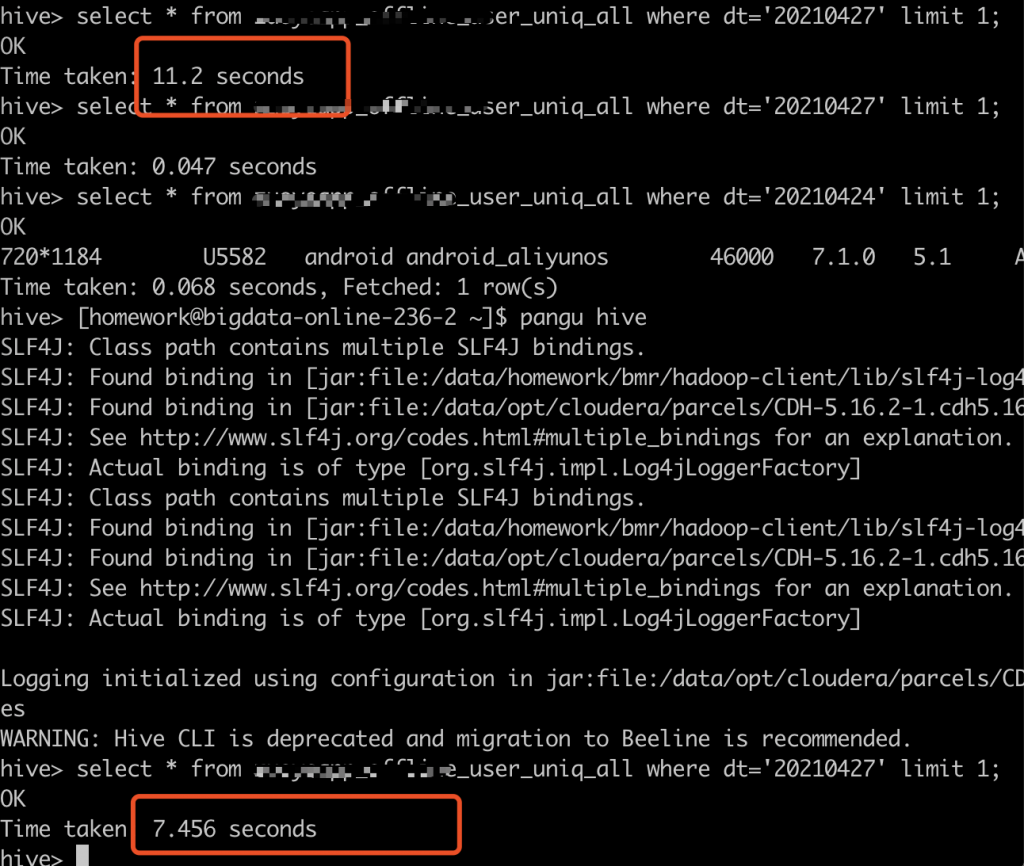
Error: Error while compiling statement: [Error 10308]: Attempt to acquire compile lock timed out. (state=,code=10308) org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: [Error 10308]: Attempt to acquire compile lock timed out. at org.apache.hive.jdbc.Utils.verifySuccess(Utils.java:241) at org.apache.hive.jdbc.Utils.verifySuccessWithInfo(Utils.java:227) at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:255) at org.apache.hive.beeline.Commands.executeInternal(Commands.java:989) at org.apache.hive.beeline.Commands.execute(Commands.java:1180) at org.apache.hive.beeline.Commands.sql(Commands.java:1094) at org.apache.hive.beeline.BeeLine.dispatch(BeeLine.java:1180) at org.apache.hive.beeline.BeeLine.execute(BeeLine.java:1013) at org.apache.hive.beeline.BeeLine.begin(BeeLine.java:922) at org.apache.hive.beeline.BeeLine.mainWithInputRedirection(BeeLine.java:518) at org.apache.hive.beeline.BeeLine.main(BeeLine.java:501) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:226) at org.apache.hadoop.util.RunJar.main(RunJar.java:141) Caused by: org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: [Error 10308]: Attempt to acquire compile lock timed out. at org.apache.hive.service.cli.operation.Operation.toSQLException(Operation.java:400) at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:187) at org.apache.hive.service.cli.operation.SQLOperation.runInternal(SQLOperation.java:271) at org.apache.hive.service.cli.operation.Operation.run(Operation.java:337) at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSessionImpl.java:439) at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementAsync(HiveSessionImpl.java:416) at org.apache.hive.service.cli.CLIService.executeStatementAsync(CLIService.java:282) at org.apache.hive.service.cli.thrift.ThriftCLIService.ExecuteStatement(ThriftCLIService.java:503) at org.apache.hive.service.cli.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1313) at org.apache.hive.service.cli.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1298) at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39) at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39) at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56) at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
doris on es 实现,列存,本地优先扫描,不排序(es 本身会排序,节省了很多计算开销),性能解决了,并且可以直接写sql了,不用写dsl了,扩展性,用户可以直接写sql了。中台必要的能力
更新场景,doris 更新不好,提升查询性能,需要做很多预计算,预计算需要有规则的。分析场景,维度跟指标要定义好,可以通过维度可以把指标预计算出来,画像场景,主键或者叫维度,更新大量是指标,查的时候要根据指标去查,某个年龄,金额大于xxx的,某个地域是xxx的人群是多少个,属性来查询。doris需要索引,排序,查询速度非常快,因为会预聚合,更新的结果应不应该在结果集中,性能会掉的很厉害,但是更新满足不了,
es 通过docid就可以更新了,性能一般,但是好歹是支持的。并且不影响读取。
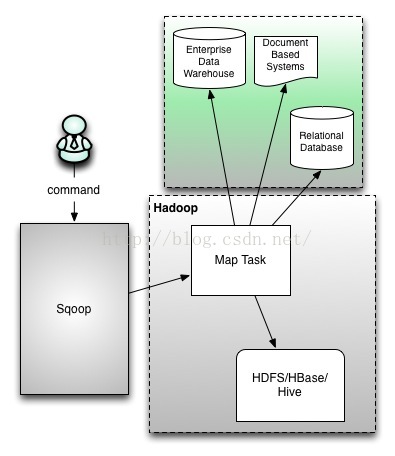
19/12/28 16:17:25 ERROR tool.ImportTool: Error during import: --merge-key or --append is required when using --incremental lastmodified and the output directory exists.
注意:可以看到--merge-key or --append is required when using --incremental lastmodified意思是,这种基于时间导入模式,需要指定--merge-key或者--append参数,表示根据时间戳导入,数据是直接在末尾追加(append)还是合并(merge),这里使用merge方式,根据id合并: